AIさくらさんに対するメモ書きみたいなもの
AIと言われる何かが社会実装された時に、どのような問題が生じるのかを考える上でAIさくらさんは非常にわかりやすい提起をしてくれたと思う。
しかし、私自身はこれをテキトーにつなげて考えたのであまりまとまっていません。すんません。
簡単な流れ
①AIさくらさんがいるみたい。
②高輪ゲートウェイ駅で導入されたみたい。
③なんか炎上しているみたい(炎上?)
④この炎上ポイントを整理したいんだけど、みんなどこに怒り(怒りなのか?この辺もよくわからない。おかしさや違和感という感じでマイルドにしてみようか)をぶつけているかわからなくなってきた。それは
・「AIさくら」そのもの
・「AIさくら」の開発者
・「AIさくら」の開発者に依頼した企業
・「AIさくら」に対して不快な質問をしている人
・「AIさくら」に対して不快な質問をしている人に対して違和感を感じている人
これらの批判が結構複雑怪奇にぐるぐるになってるのだ。表現の自由を持ち出すパターンもある。、過剰反応とかそういう意見もあってややこしい。
「AIさくら」に対して不快な質問をしている人の違和感はわかりやすい。「機械に対してもそういう質問をするもんでない」。そしてそこから「大体なんでそういう会話をできるようにしておいたんだ」という話に持っていくのは容易である。だってこれAIさくらという人格が存在してそいつが勝手に生み出したわけじゃなかろうて、後ろにそのような設定をした開発者がいるってことなのだから。そしてそれにOKを出した人間がいるってことなのだから。そういう発言を許容できる企業や社会って変じゃないかという問題提起である(と思っている)
これは「AIさくら」に対しての違和感よりも、それらの行為を許容している社会に対しての違和感である。*1
もちろんこの違和感に対して批判や対案があってもしかるべきだ。*2
例えば相手が機械という立場を利用して、AIによって人間に対するセクハラを防いだという言い方をすればどうだろうか。人間中心で考えると、そういう発言をすべて機械に受け流すことができ、人間に対する被害を防げるだろう。
ところがだ。機械に対してだから何をしてもOK、機械が言ったから何をしてもOKというのは、あり得るだろうか。少しこの前も、後者の意味で議論があった。
では、前者に対してはどうだろうか。
少し前の記事だが、ロボットに蹴るという行為を加えても、ロボットは安定しているというデモを紹介していたが、批判もあったらしい。
「ロボット犬」蹴り飛ばすのは虐待!? 「ドラえもん」も巻き込み議論が白熱 : J-CASTニュース
実態を伴ったから問題視されたのか、そんなことはない。架空の存在であっても、それは問題化する。ある学会が(機械だからこういう表現も可能ですよね系)問題で炎上したのだ。学会「表紙」に対してである。
JSAI表紙問題はなんだったのか
昔(といっても6年前の話だけれど)にこういう事があった。
ほうき持つ女性型ロボットの表紙 人工知能学会の「お詫び」、過剰反応では : J-CASTニュース
(あまりいいまとまりかたをしたニュースがないな・・・)とまあ、炎上したのだ。
これに対して、JSAIはこのような回答をした。
「人工知能」の表紙に対する意見や議論に関して – 人工知能学会 (The Japanese Society for Artificial Intelligence)
「ロボットが女性型をしている」「それが掃除をしている」「ケーブルでつながれている」等の要素が相まって、女性が掃除をしているという印象(さらには女性が掃除をすべきだという解釈の余地)を与えたことについては、公共性の高い学術団体としての配慮が行き届かず、深く反省するところです。
当時すでにルンバがあって床掃除ができた時代、掃除をするという行為に「人型」でしかも「女性」をもってくる必然性なんてなかったのだ。もちろん製作者に何らかの差別的意図があったわけではない(同サイトから、製作者の制作意図が読める。ぜひ読んでいただきたい)。
この時人工知能学会はおそらくこういうことを学んだはずだ。
「インタラクションを生むために親和性は重要である。ところが、この親和性が社会・公共の場に出たときに、どのような解釈を与えるかは別問題である。」という点である。この問題は表紙だけであったが、実研究・実装にも延長されるテーマであったと思う。*3
サブカルチャーのよる親和性向上は研究においては評価可能であり、ポジティブなものとして受け入れられたかもしれないが、社会においてはどのような意味を持ちえるかは、さらなる検討が必要だったはずだ。*4
この場合の「AIさくら」はその社会実装の前段階に、様々な人の視点が必要だったはずだ。親和性によってどういう振る舞いを人間はしてしまうのだろうか。特にジェンダーステレオタイプを意識するようなデザインやインタラクションを引起す場合。「親和性が高いが人間ではない存在がいた時、人間にはできないようなコメントをする人間がいる。そしてそのコメントを受け入れられる社会ではない」と気付くならば、そういうコメントに対する、プロテクトは組み込めたかもしれない。
JSAIの表紙問題は、ロボット・AIエージェントが研究者界隈の考えでは足らない(かもしれない)「実社会」がつねに存在しているという視点を与えていたはずだ。エージェントを作るということ、ロボットを作るということは、決して独りよがりのものではなく、社会からどのように見られているかを考える必要があるということを。
ところでロボットの性差とはなにか?
ところで今回私が議論したいのは、ロボット(もしくはAI)に対して性差とはどのように現れるのかということなのだ。なぜか。画面に映って対応してくれるエージェントにさえこのような反応があるのだ。性差というものを要素(こういう役どころにはこういう性別が親和性いいよね〜)ではなく、1つの立派な概念として考える必要があるのではないか(そもそもロボットに性差を組み込むことは現代の社会的にどういう評価を受けるのだろうか)。
もしロボットだけの世界だったら、ロボット達だけに決めてもらえば良い*5。ところが今回は人間を含む巨大ループである。そういうした時、機械の性差とはどのようなものとして現れ、捉えられる必要があるのか。
うー。続きは後編で・・・。やるのかなぁ・・・。
*1:私はこう解釈している。だけど、それがすべてかと言われればそうじゃないかもしれない。僕はフェミニストでもないしその方の研究については専門外だから発言する責任を持ち合わせていない。僕ができるのはせいぜいなぜこのような問題が発生するのかを考えるだけだ。あと、僕は普通に可愛いキャラクターがいたら嬉しくなる
*2:ところがネットに上がっているこの上記の違和感に対して誠実な回答をしているのかと言われれば、なんとなく引っかかる点がある。
「クローズドな環境だからいいじゃないか」
「表現の自由だ」
「AIさくらが可愛そうだ」
これらは上記の違和感に答えているのだろうか?いやおそらく答えていないだろう。違和感に対しては、誠実にその違和感の原型を解き明かすしかないのだから。
というか、その考え方感じ方きめえみたいなこと平然と言えるのどうなのか。というかそういうふうに言うから悪意増長するんでない?というかTwitterでの議論は他者性を入れないから、個人対決になっちゃうところが問題だと思う。なんだかな・・・。
*3:この後人工知能学会が表紙に対してどのように考えているかについては、大澤博隆. (2015). 2015 年表紙更新にあたって: 前年の 「表紙問題」 のまとめとこれから (アーティクル). 人工知能, 30(1), 2-6.を参考に。
*4:そのためには事前に炎上を経由することも必要かもしれない。そうした「安心して炎上できる場」をいかに作るかが大事なのかもしれない。安心して炎上できる場については→
*5:と思っている私の人工生命ラディカル主義が心のどこかで存在している
スクリプトの外側にあるスクリプト
二郎系GANは富山ブラックラーメンの夢を見るかの続きのポストである。まず私の問題意識を知っていただきたい。
しかし書いてみて、どうあがいても二郎系に結びつかない。なので、新しいタイトルで0からのスタートを図りたいと思う。(ときすでに遅し)
まえがきにならないまえがき
二郎系GANは富山ブラックラーメンの夢を見るかで私はこんなことを言った。
後編では、更にそのデータの外側に目を向けて、どうすれば、人間と同じように人工知能がデータの向こう側を感じるようになるのかを考えていきたい。
どうやら私は寝ぼけてそんなことを書いていたみたいだ。パターンの外側にあるパターンというものを感じ取る。かなりアバウトな話であるなと投稿から、10日間たって思う。データの外側にありえたかもしれないパターンってなんだ。どうやって人間はそれを作り上げているのか。と。しかも機械にそれを組み込むとは?
人間はデータの外側にあり得たかもしれないパターンを(もしくは秩序を)自分勝手に生み出しているのだ。それが真のデータと異なっていても、予想としてそれを想像したり妄想したりする。
結局の所、私はその「妄想」に支配されているだけかもしれない。しかし、妄想を現実にしてきた生物ーつまり人間ーの力とは侮れない。この力の駆動源や駆動系を議論することにこそ「知能」に迫れるのではないか。こういうことを議論してもバチは当たらないだろう。もしそれが構造的に決定できるのならば、機械にだって置き換えることはできるはずだ。それが人工知能ではないか。なんて思ったりもする。
そこで、今回はスクリプトに焦点を当ててデータの外側についての理解を深めていきたい。個人的に、スクリプトの外側について議論をするのは、イラストのデータの分布より難しいが例えることが容易であると判断したためである。
スクリプトの外側をどのようにして人間は開拓していくのか。そしてその開拓した部分をどのようにして広げていくのか。
対抗するわけではないが、近年の自然言語処理(NLP)界隈では、データを盲目的に収集する人工知能、データ内部の特徴量構造を獲得するためのシステムが流行っている(これがすごい技術だから何も言えないのだが)。すこし引きで見ると本当に「知能」なのかと自問自答したくなる。データを食わせる、そして内部の特徴量をより細かくみる。それが知能なのだろうか?
私はあくまでも人工知能で知能に迫りたいと思っているのだ。それは途方もない夢かもしれないが。
前回のポストで足りなかった部分を脚注で付け加える。*1
スクリプトの外側
スクリプトの外側を考えるためには、スクリプトを用意して、その内と外の違いを見てみるのがいいのではないか。
種類にもよるが、とりあえず演劇のスクリプト(台本)を上げてみよう思う(あくまで私の趣味なのだが)。演劇のスクリプトは、スクリプトの外側とはなにかということを考える上で利点がある。
演劇はスクリプトの外側が簡単に出てくる。スクリプトの外側がむしろなくてはならないのだ。もしスクリプト(地の文)だけで演劇をしようとするならばとんでもないつまらない。シェイクスピアも筆を勢いよく居るだろう。
演劇はおそらくスクリプトで書かれたの外側に何かが存在するからこそ(そしてそれが無秩序でないからこそ)、古代ギリシャから現代にかけて観客を、役者を、演劇に携わる人間を魅了してきた。
スクリプトの外側、それは役者の動きも1つだろう。そしてセリフになりアドリブである。
ここであるスクリプト*2を見よう。舞台設定はある高校の授業終わりの昼休みである。
ピザ屋 こんにちはー、ピザCATです。
榎木 何ですか、あなたは。勝手に入ってこないでください。
ピザ屋 ピザの配達にまいりました
榎木 ピザの配達?そんなもの、誰も・・・。
紫藤 (むくっと起き上がり)あ、それ、僕です。
榎木 紫藤、お前な・・・
黒田 (赤間に)あれ、お前食べないの?
赤間 うん、ダイエット、ダイエット。(お腹がなる)
高校生がピザを頼むというのはかなり無理があるだろう、がそれは本題ではない。この部分のスクリプトは、授業終わりで弁当を食べるシーンなのだ。授業終了後、紫藤がピザを頼み、先生である榎木が呆れ返っているシーンだ。しかし登場人物は彼ら5人だけではない。黒田や赤間が話を続けようとする。さらに、10人以上の高校生役の役者がその舞台に立っているのだ。
ただ突っ立って・・・?そんなことはない。彼らは彼らの舞台上の関係性を持って、何かを話しているのだ。いわゆるアドリブ*3である。
このアドリブこそパターンの外側を考えるヒントになるのではないか。我々はスクリプトにはない言葉を、スクリプトを利用して生み出している*4。
このスクリプトをじっくり見ると、榎木のセリフのあとに次のように続いていることがわかる。
榎木 紫藤、お前な・・・
黒田 (赤間に)あれ、お前食べないの?
赤間 うん、ダイエット、ダイエット。(お腹がなる)
変哲のないスクリプトだが、この3行から、スクリプトの外側にあるパターンを役者は大量に生み出さなければならない。榎木は「お前な・・・」というセリフのあと、何かを言おうとしている。しかし、メインスクリプトは黒田と赤間に変わっている。ストーリ的には黒田・赤間が優先されるが、榎木がそこで停止しているわけではない。その後も紫藤に対してなにか言わなければならない。何をいえばいいのか。
もう1つは黒田と赤間に対してである。榎木と紫藤、ピザ屋がやり取りしている間、二人は突っ立っているわけではない。黒田は赤間に何も食べていないことをこのやり取りの間でおそらく気が付かなくてはならない。
短いスクリプトからスクリプトに書かれたこと以外を想像しなければならない。
おそらく榎木は紫藤に「いくらなんでも、ピザはないだろう」とか、紫藤が榎木を無視して「いやあ、ピザ食べたかったんですよ」ということも想像できるだろう。他にも考えられる、ピザ屋が「代金です」といって、紫藤に向かってピザ代を請求する。お金を持っていない紫藤は、榎木に「先生ごめん、立替えてくれ」というアドリブも可能なのだ。こうしてみるとこのスクリプトの外側は自由度が高い。しかし自由度が高いが、無秩序ではない。なぜならば、おそらく榎木は「俺も食べたいな」は言わない様なきがする。なぜだろうか。
もう一つの例はややこしい。紫藤と榎木がバトルしている際に急に乱入するスクリプトである。黒田はどのようにして赤間が弁当を食べていないことを気づくのだろうか。無関係で進行していた二人がいきなり榎木のセリフにかぶるように話すこともありえない話ではない。しかしそれは可能性の1つである。急展開で話が展開されるのではなく、その前におそらく様々なアドリブが生じることが期待できる。例えば赤間から「黒田の弁当美味しそうだね」と言って会話が始まることもあれば、黒田が「なあなあ、今日の弁当なに?俺はね・・・」という自分の弁当を自慢することから始まるかもしれない。それでもおそらく、赤間が「こんちくしょう。ふざけやがって」とは言わない様な気がする。
スクリプトの外側にあるスクリプトを予期する役者。しかしそれはスクリプトで書かれたパターンからの逸脱ではない。そのパターンを予期して、アドリブを生成する。自由度は高いが逸脱ではないのだ。スクリプトの外側にあるスクリプトを予期して我々はスクリプトのないスクリプトを生成しているのだ。役者に限ることではない。観客もそれを自然に予期してしまう。
だからこそ、セリフ(榎木の「食べたいな」や赤間の「こんちくしょう」)は当てはまらないのかもしれないと思ってしまう。この8セリフという短いスクリプトでさえ、我々はスクリプトの逸脱さえも予期する。それは我々がこの8個のセリフに対して、見えない外部を予期し、自然なスクリプトを構成しているからかもしれない*5。
スクリプトの外側は内側ではないか?
しかしこれについて簡単に反論があるかもしれない。
この様な日常シーンは前にも存在したのではないか。似たようなセリフがスクリプトに書いてあるのではないか。だからパターンの外側では厳密ではないんではないか。*6
つまりこの様なアドリブは、スクリプトのどこかに同じ様な文章が書いてあるからこそできるのではないかという反論である。確かにそうかもしれない。3幕目でこのスクリプトがあるならば、類似したスクリプトが2幕目や1幕目に出ているかもしれない。ここで全スクリプトを上げるのは引用上困難である。なので、私が嘘をついて上記のアドリブを、スクリプトのどこかから持ってきて再構築している(私が私自身を人工知能化している)だけかもしれない。
身近な例でいうと「まんがか」のセリフを創るために大量のデータを利用している・・・そんな感じだろうか*7。この場合は、スクリプトの並び順を飛ばしてキャラクタのスクリプトを再構成したものを表示している。最近の研究では、言語(スクリプト)もGANで生成できるようになり、かなり精度が上がっている*8。なるほど、それらしい文章はデータさえあれば作れるのだ。スクリプトの内側に存在すれば、我々は新しい文章を生成することができる。
そうであれば、役者がという職業はただ単に、スクリプトをどこかから拝借するだけの自動機械になる。それはそれで機械にとって現状でも難易度は高いのだが。
しかし、アドリブは必ずしもスクリプトの内側に存在するものではない。役者がスクリプトにないセリフを話そうとするとき、それは定常状態の場面だけではない。事件が起こり、なんとかしなければいけないというときに、今までにない新しい言葉を作らなければならなくなる。そのとき、そのセリフはスクリプトの内側を見ていても永久に見えてこない。舞台は動き続けるからだ。
舞台が動くとき
例えば先程のスクリプトの続きを見てみよう。
榎木 よかったな、赤間。これでお腹いっぱい・・・
赤間 ・・・いらんし
榎木 え?
赤間 こんなん、いらんし!先生ひどい!
少し間をおいてこのように話が展開していく。そこには、「ダイエット」と言い訳をして昼ごはんを食べなかった赤間の姿はいない。 舞台が動く瞬間である。緊急事態だし、スクリプト全体をみても1回もそういう状況にはなったことがない。
それでも役者は食らいつかねばならない。その役者が何を言っているか・・・。その時何を言うべきなのか、何を行動しなければならないのか。これらはスクリプトにはない。今までのスクリプトには決してのっていない。役者は、台本に書かれている「安易なキャラクター」からハズレ、スクリプトの外側にある、そのキャラクターの延長を、スクリプトがなくとも演じなくてはならない。しかし、そのスクリプトの外側は、その状態に対して秩序的なものを持っていないといけない。
ここで例えば紫藤が「ピザのお金明後日返すわ」とか言ってもいいのだろうか。まだ紫藤ならという感じもする。紫藤というスクリプトの外側にはこの状況と対峙しても、このセリフが出てくることがまだ予期される。「おい、赤間」といって追いかけることもできるだろう。「あーあ。なんかかったりーな。別の教室でピザ食うわ」でもあるかもしれない。
しかし、無限にアドリブが用意されているわけではない。例えば、いきなり「うんちょこちょこちょこぴー」と発言した場合どうだろうか?スクリプトの外側に存在する言葉である。だが、紫藤はそれを言うことができるのだろうか。確かにスクリプトの外側にはある。もしここで紫藤(を演じる役者)が言ってしまった場合、演出からこう言われるだろう。
「お前は何を言っているんだ」
もし大会ならばこの瞬間予選敗退が決定してしまう。そして、周りの同級生から3週間ほど口を聞いてもらえない状況になる。
それだけ「うんちょこちょこちょこぴー」はおそらスクリプトの外側には存在しないような気がしてしまうセリフなのだ。
ではなぜ同じデータの外側にある文章であるにもかかわらず、そこに線を引くことができてしまうのだろうか。つまり、上記のアドリブはスクリプトの外側であり、「うんちょこちょこちょこぴー」はさらに外側のランダム的エリアに入ってしまっていると我々は思ってしまうのだろうか。
映画を見ているときでも我々はそういうことをしているはずだ。おそらく、ストーリーがちゃんと理解できるとき、われわれは次のシーンを予測しながら観ている。ところが、とんでもないことが起きるとき(舞台が動くとき)、私たちは妙な感覚を感じる。それは、自分の中にあるスクリプトから大きく逸脱したからだろう。それでも、私たちは瞬時にその逸脱したスクリプトを利用して新しい外側を作っていくことができる。しかも無限にあるストーリーから、限定的なスクリプトを利用して秩序的な見えないスクリプトを作っていく。
ドラえもん映画を見ているとき、鉄腕アトムの登場を我々は予期しない。(手塚治虫は平気でそういうことをやるのだが…。)
舞台が動くとき、スクリプトの外側にあるスクリプトを作っていかなければならない。そうでないと我々は映画どころか生活も楽しむことができないのではないか。
スクリプトの外側にあるスクリプトを生み出す力
この我々のスクリプト秩序的外側と、その向こう側ランダム的な部分に線を引いて、その範囲内で物事を考えること。スクリプトの外側にあるスクリプトを考えるとき、スクリプトの内部から外側を見つめ、ランダムと秩序に線を作り、新しい秩序を再構築する能力。
スクリプトの外側を作っていくとき、永遠に終わらない対話がそこに存在する。アドリブを言うときに、瞬時にこういうことを計算しなければならない。このセリフはありえるだろうか?いえるセリフの限界はどの辺だろうか。流石に無理がある。いくらなんでもスクリプトの外側にはこのセリフは存在しない。我々はスクリプトの逸脱さえも予期している。逸脱した結果そのセリフは棄却され、スクリプトから放棄される。
このように、アドリブをするためだけに、役者は秩序的なスクリプトの外側を見つけようと、今までのスクリプトと照らし合わせながら再構築しているのかもしれない。出てきたアドリブがパターンの外側の秩序的部分であるかそれとも、逸脱か。自己言及を繰り返しながら、そして外に(我々に聞こえるように)セリフを出す。
セリフが適切だった(何が適切かは議論が必要かもしれないが)場合、そのアドリブは舞台演出を効果的に盛り上げる。もしランダムと秩序のぎりぎりを言ってしまった場合、それはさらに深いものになる(お笑いはそのエッジがさらに研ぎ澄まされた状態だと思うのだが)。
スクリプトの内側を探求するだけではない、外側を作っていく力。 外側は内部の見えない構造から影響を間違いなく与えるだろう。今あるスクリプトが正しく認識できない場合は、スクリプトの外側を探求してもランダムなものになってしまう。スクリプトの内側をちゃんと認識することで、外側にあるべき新しい秩序を生み出せるかもしれない。スクリプトの外側を見つけるためにはは、既に存在する秩序(データ)からあるはずのないスクリプトを再構成しなければならない。
それは「パターンの外側」を自己生成する力である。そしてパターンの外側と内側のぎりぎりを見つける力である。
その力によって、まっとうなアドリブや、逸脱したアドリブ不気味なアドリブを感じてしまう。もっと大きい話ならばストーリー展開さえも予測できる。限られたデータから、データの外側の秩序、その内側を限られたデータから再構成し、そしてそのエッジ(edge of chaos)のぎりぎりまで自己言及し続ける*9。データの内部を見つめてもそれはできない。その向こう側を作るためには、データの内部を飛び出さなければできない仕事である。
自己言及は、自分だけではなく、他者と出会うことでさらに洗練される。例えば、アドリブを一度外に出し、相手の承認を受けると(練習で演出に今のアドリブいいねとか言われると)、そのアドリブはスクリプトの内側に組み込まれる。内側に存在してもよいという許可を得られたスクリプトは、それをもとにさらに外側を探求して新しいアドリブを見つけることもできるだろう。
これらの能力は、単なるデータ内部からの延長ではない。自己言及による、外側の再構築、再発見が必要ではないだろうか。
だからデータを食わせれば良い問題ではない。失敗しても自分の中でランダムと秩序の間を見つけていく創発作業によって生まれる。外側をどのように進むのか。それが一つの向きだけでは多様性が保証されない。個体差、個性によってデータの外側は様々な方向に広がっていくだろう。また、データの内側をより鋭く見れる存在は、さらに外側への再構築に対しても鋭敏ではないだろうか。様々な予測がたてられる。
機械にデータの外側を見てもらいたい
さて、問題はこれらだ。もしこれらの議論がある程度正しいならば、機械に必要なのは、外側の予期と再帰的な自己への取り込みである。
どうして我々は、外部を予期できるのだろうか。どうやって端っこを確認しているのだろうか。
果たして機械でできるのか?機械はどのような仕組みなのか。そしてそこに知能は存在するのか?これらの問題をを考えていきたい。
ご意見やご感想がありましたらコメントをぜひよろしくお願いします。また間違いの訂正もぜひよろしくお願いします。
*1:ところで、生成系システムと分類システムは根本的に違う。AE(オートエンコーダ)の中間層が生成系で利用しないように(AEは原理的にはできるのだが、考え方は分類や〇〇と同じである)、分類システムが生成でそのまま利用することはできない。しかし、データを空間で認識するという点においてはおおよそ同じであろう。であるから前回、線形分類を例にとって私の考えを伝えたかった。NNは線形分類できる形に変形している。なら、その端っこはどうなっているかと・・・。4と7のクラス分類の端っこはそれでも4と7なのか。機械学習的にはそれはYESだ。そこには学習したデータは存在しない。ところが、我々はそのパターンの外側に存在するパターンを感じ取ることができる。
機械にとってはずーっとそれは7のクラスなのかもしれない、そこには何もないのかもしれない。では、人間はそれを超えることはできるのか。
それが本ポストの主題である。
*2:2008年中部日本高校演劇創作脚本集・中部日本高校学校演劇連盟より「食べ終わるまで残ってなさい」中山みるく著 から引用
*3:本来はアドリブとは音楽用語であり、演劇では動きもアドリブの一部に入る。しかし今回はスクリプトの話をしたいので、セリフアドリブとして言及していきたい
*4:アドリブを認めるか認めないか、これは演出によってかなり差がある。完全に舞台をコントロールしたい演出はアドリブさえもコントロールする。今の所幸い私はその様な演出に出会ったことがない。しかし、本文でも記述したが、アドリブは1回目はアドリブなのだが、2回め以降は、スクリプトになってしまう。それでも多彩なパターンが出るということは、アドリブはスクリプトの外側の秩序的な無限性を秘めているような気がしてならない
なお、ここでのアドリブとは、スクリプトの裏側に潜むアドリブであり、スクリプトを自分勝手に書き換えて変更することではない。あしからず。
*5:もしお笑いならばこれらのセリフは成立するかもしれない。セリフにかかる文脈依存は、何もスクリプトの表面的意義ではなく、かなり深い問題に根付いていると私は直感的に感じている。文脈によって正しくなる・もしくは正しくない(笑いに変換される)スクリプトが存在するというのは、スクリプトの外側を別の面で拡張する際に様々なレイヤーを生じているのではないか
*6:もっと大きい反論として、スクリプトの外側は、我々が生活してきてなんとなく生じているものじゃないのか?というのがあるかもしれない。でもこの大きな反論は内側と外側を切断する人工知能にとって致命的な反論である。この問題はおいおい考えていきたい
*7:
*8:言語処理におけるGANの展開のスライドが公開されていた。翻訳だけかと思ったら、生成でも利用されている。また古典的にはマルコフ連鎖を利用したデータベースをもとにした言語生成や、単純なリカレントニューラルネットワーク(LSTMが多いかもしれないが)を利用した言語生成の研究もある。
二郎系GANは富山ブラックラーメンの夢を見るか
なぞのまえがき
タイトルの旧題は「パターンの外側にあるパターン もしくはスクリプトの外側にあるスクリプト」であった。ブログを書きつつ新しいタイトルが出てきたので、そっちに切り替えた。 更に前後半に分けるという長いポストになってしまった。
生成系ネットワークの面白さ
近年(といってももう2~3年前くらい)から注目されている深層学習の研究にGANというものがある。GANとは、Generative Adversarial Networkの頭文字をとったものであり、直訳すると「敵対的生成ネットワーク」である。「生成」というからには、なにか生成するのだろうというのが容易に推測されるが、この生成が生半可なレベルではない。近年の深層学習系の国際会議ではGANの投稿が多い。
注意:この投稿ではGANの詳しい説明はしません。というか、いろんなサイトがGANの説明していますからね。今更私が説明しても…(いや、説明しないとお前理解しているんか本当にということになりかねない・・・汗どうすればいいんだ汗とりあえず、GANのおすすめサイトを提示しますので許してください。)

この図をみてもわかるようにGANの亜種というかGANをベースにした研究は山程されている。(ちなみに図は以下のサイトからの引用である。ライナー?これライナーだよね・・・汗。頼むライナーであってくれ。)
そんなGANZOOにとんでもないものが現れた。昨年末、研究界隈突如に現れた最新のGAN「Style-GAN*1」が蓋を開けてみたらとんでもないGANであった。このStyle-GANでは生成方法に少しトリッキーな方法を利用している。GANはノイズ(だいたい正規乱数だったりするわけだが)から画像を生成するが、Style-GANではノイズに加えて、Styleと呼ばれる生成画像を制御する情報を加える。
このトリックにより、存在しそうであるが、全く新しい画像を生成することが可能になった。(GANそのものでも「ありそうであるが、全く新しい画像を生成することは可能であったが、このStyle-GANはその制御を細かくすることが可能である。)
Style-GANを使った様々な生成が試みられている。Twitterでは様々な生成が試みられている。
StyleGANのアニメキャラクター生成.すごい pic.twitter.com/ALd675mjLL
— Ryobot | りょぼっと (@_Ryobot) 2019年2月12日
約9万枚のラーメン二郎画像で StyleGAN を試しました。
— Kenji Doi (@knjcode) 2019年3月5日
公式の実装を使って、最大解像度を512x512pxに下げて学習しています。
まだ学習途中(50%ぐらい)ですが、以前のPGGANよりさらにリアルになっているように思います。#ラーメン二郎 #GAN pic.twitter.com/HWZzWIOn9a
これらの画像は「いままで存在したことがない」画像であり、新しい画像である。
このように生成をすることで、不足している学習データの水増しなどにも利用することもできる。近年の機械学習ではデータの量が重要視されており、いかんせんデータ不足で泣くこともある。そういうときに生成系の「今までのデータには存在したことがないけれども、データの分布上に存在する新しい存在を創る」という能力は貴重だろう。
また、GANは画像だけでなく音楽や文章の生成にも利用されている。
さてここで生成系、特にGANの説明を終えることとする。
GANがすごい、じゃあ何もいうことはないのか。いやそんなことはない。GAN生成の魅力はは「あり得たかもしれない画像を生成する」能力である。しかし、人工知能研究者はその「あり得たかも」しれないという点に敏感に反応しなければいけない。
「あり得たかもしれない」新しいデータ集合{Xi}
生成系で「あり得たかも」しれないデータは、学習するデータに存在するパターンの内側だろうか、それとも外側だろうか。学習データのパターンの内側、外側という言葉が出てきた。少し分かりづらいので、ある例えをしてみよう。
二郎系StyleGANは、あり得たかもしれない二郎系ラーメンを生成する。
一方、二郎系ラーメンの写真を眺めながらふと私達は思う。「そういえば富山ブラックラーメンなんてのもあったよな。汁がメッチャクチャ真っ黒いやつ。あれ美味しいのかね」
二郎系画像を眺めながら二郎系以外のラーメンの存在に思いをはせる。画像では決して見ることのできない富山ブラックラーメンを。
ここで確認したい。私達と機械は同じ「二郎系ラーメンのデータ」を食っているのだ。
GANはーーー二郎系ラーメンのデータを沢山食わせたGANはーーー二郎系っぽいラーメンを生成している。ところが人間は二郎系ラーメンから二郎系ラーメン以外を生成している。「あり得たかもしれない」の質が異なるのだ。
データの内側と外側。それは、食わせたデータに依存する。データの分布に存在するのが内側。存在しないのは外側になる。GANは食わせたデータの内側を旅するのだ。「あり得たかもしれない」新しいデータ集合は、データの内側ある未知なる空白地帯を旅して生成している。
内側にある未知なる空間を探索するGAN。GANの生成は学習データの内側である。学習データの内側…学習したデータと同じ分布になるように学習を行う生成系であるからこそ、我々に未知なる内側を見せてくれる*2。しかし、生成系ネットワークはその外側にある存在を映し出すことはできるのだろうか。
一方、私達はパターンの外側にあるパターンを認識することができる。それは二郎系ラーメンのことを想像しつつ同時に別のラーメンを想像することからも簡単にイメージができる。しかしそれはデータ内部には記述されていない。二郎系にラーメンに富山ブラックラーメンの要素はラーメンというコンセプト以外存在しないのだ。にもかかわらず、二郎系以外にも家系でも富山ブラックでもラーメンのパターンをいくつも思いつくのだ。
それは多分、我々はデータの内部の空間ではなく、データの外側にあるはずのパターンを探し続ける存在だからだ。それもどこまでも。しかし、おそらく秩序を持って(これは後述する)。
パターンの外側と内側の間で
生成系の話を少し特徴量空間で考えるために、トリッキーかもしれないが、単純な線形分類問題を考えてみよう。*3
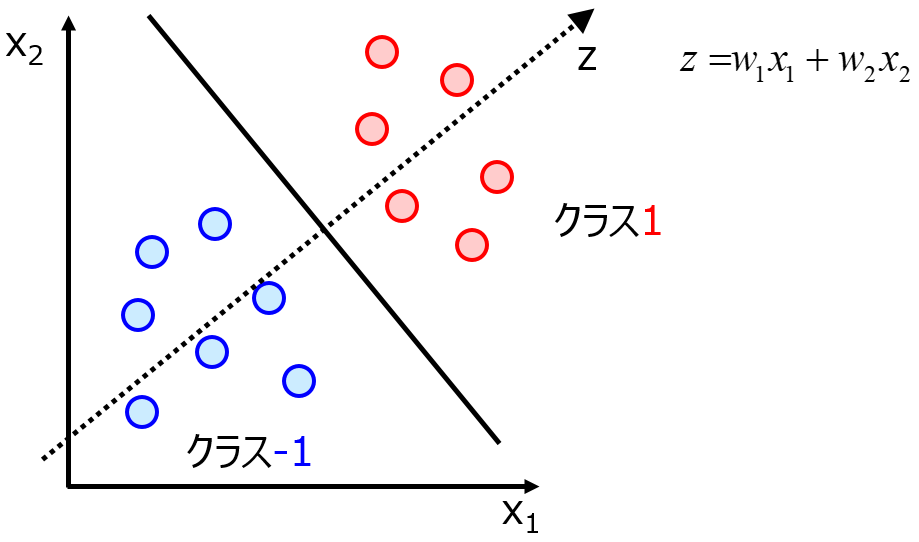
適切な画像圧縮をすることができた結果、研究者は画像データを潜在空間に押し込めることができた。この潜在空間の情報を利用して、2つのクラス分類をしようとする。なんのことはない、このクラス-1とクラス1の間に線を引けば良い。単純な線形分類だ。(ニューラルネットワークだと、このへんの線の引き方を巡って一悶着している。 Adversarial exampleとかその一つだと思うし、これは今後扱いたいテーマだけど今回はそっと閉じておこう。)
このクラス1をMNIST*4データの7として、クラス-1をMNISTデータの3としておこう。なるほどデータの中心は、だれからみても7だし、片方は3であろう。ではここで、潜在空間から無理やり頑張って、我々の目に見える形でデータを復元しよう。潜在空間の変数からデータを復元するのだ。*5。
では、データ分布中心からどんどん端っこの方へ歩いていこうとしよう。潜在空間を散歩していくのだ。どんな画像が現れるだろうか。「7」のデータ分布の中心から歩いていこう。
線形分類上そこは、機械にとっては「クラス1」、「7」を指し示している。はじめの方は「7」が見て取れるだろう。どんどんデータ分布からはなれてみよう。すると、我々の潜在空間を通して生成された画像はもはや「7」には見えない。ぼやけてしまってなんの図形になるか認識できなくなっている。しかし、機械は言い張るのだ「ここは7の領域なのだ」。
一度線形分離で定めたクラスの分離領域以外には、境界が存在しない。いくらデータ分布から外れていようが、機械はそこで外側や内側を決めることができない。特徴量空間の端っこには学習したデータは存在しない。それなのに「外側」という認識ができないのだ。データの外側という概念がそもそも存在し得ないのだ。
生成系のシステムで同じように考えてみよう。
二郎系GANは二郎系のデータの内部では流暢だ。しかしGANはその特性上、学習したデータ分布がうまく決定できず、データの外側の画像をふと生成することがある。その瞬間、二郎系のデータから学習したにもかかわらず、全く意味のない画像を生成してしまう。富山ブラックラーメンや家系ラーメンは出てこない。ただそこにあるのは、ランダムノイズでラーメンかどうか我々には認識できない画像が生成される。*6
データの外。それは学習データとは全く関係がない、全く秩序を立てることができないノイズでしかない。機械にとってはデータの外側は意味を持たない、パターンも存在しない無秩序の存在でしかない。ラーメンは現れないのだ。
しかし人間は、おそらくパターンの外部にパターンを見出すことができる。もしくは感じることができる。私達は「8」や「2」を想像できるかもしれない、もしくは新しいなにかを思いつく領域である。それこそ富山ブラックであり家系ラーメンなのかもしれない。しかもしれは、意味のない画像ではなく、新しいラーメンを生成しているのだ。(もしかして創発なのかもしれない)
人間はデータの外側にあり得たかもしれないパターンを(もしくは秩序を)自分勝手に生み出しているのだ。それが真のデータと異なっていても、予想としてそれを想像したり妄想したりする。
この学習データのパターンの外側にあるパターンを生成する我々と、そうでない生成系。データの外側に着目すると、人間と人工知能の違いは明確になる。
後編では、更にそのデータの外側に目を向けて、どうすれば、人間と同じように人工知能がデータの向こう側を感じるようになるのかを考えていきたい。
なお、このポストは次の本から多大なる影響を受けている。
")
ご意見やご感想がありましたらコメントをぜひよろしくお願いします。また間違いの訂正もぜひよろしくお願いします。
2019/03/22 一部文章修正(GANの生成の問題点のあたりで変ないいまわしがあったため)
*1:
などの説明をどうぞ。また論文は
[1812.04948] A Style-Based Generator Architecture for Generative Adversarial Networks
こちらから。
*2:もし生成系が分布に依存しない新しい画像を生成してしまったら評価のしようが無い
*3:線形分類問題の図は以下のサイトから引用しました。https://datachemeng.com/lineardiscriminantanalysis/
*4:MNIST(Mixed National Institute of Standards and Technology database)とは、手書き数字画像60,000枚と、テスト画像10,000枚を集めた、画像データセット。https://udemy.benesse.co.jp/ai/mnist.html より。
*5:GANのことをギャンギャン言いながら、この生成方法はVAEではないか。VAEの生成についてはこちらから
*6:特に初期のGANでは、そういうことがあった。DCGANではなかなか生成されず、おそらくデータの分布の外側へ行ってしまったようなものが生成されてしまう。
画像は以下のサイトから引用しました
認識フレーム問題とタスク依存性について(2)
自由自在にフレームを作り変えることができる知能
前回にフレーム問題の簡単な説明を行った。そこでは、強化学習はミクロレベルの問題は解けるかもしれないが、マクロレベルの問題は未だに解決できないのではということを考察した。マクロレベルの問題とは、同じ目的でも環境や報酬が変化してしまうとタスク依存性の観点から、対応できなくなってしまうことである。
今まで人工知能の研究は非明示的にタスク依存の研究をしてきた。特に最近の強化学習のベンチマークはゲームを解くことや、与えられたタスクを解くことが1つの指標となっており、強いタスク依存性を持っているのではないか。これは、日常生活で我々が行っている生活に比べて、限定的な知能を作る方向ではないかと感じている(これは私の感覚なので間違っているかもしれない)。
様々な強化学習の研究で、汎化性能を持たせようという研究があるが、それでもやはり与えられたタスク(ある意味研究者が強化学習の神様になって与えたもの)からは逃れられない。*1
ここまでの話は今までの人工知能の研究からすればナンセンスに感じるかもしれない。なぜならば今までの人工知能はある意味あるタスクを解かせようということに注目をしてきたからだ。だからタスク依存性という言葉は少し人工知能の研究からすれば当たり前だし、それを取っ払って問題を考えることは途方もない課題のように見えるかもしれない。
しかし、人間はタスク依存性を攻略しているかのように見える。少なくとも今の段階の人工知能よりかは。そのあたりの雰囲気や自分の感情状態を加味して、欲求を作り上げ行動する(外からは目的をみつけて適切なタスクを構築しているように見えるのかもしれない)。このように自分の中で自身の欲求、感情や知識ををフレームとして構築しているのかもしれない。
このように人工知能の問題も、タスクベースで考えるのではなく、フレーム構造を作り上げるというふうに捉え直すことはできないだろうか。つまり主観的輪郭を加えるのである。
ただし、人間もフレームを自由自在に操られているかと言われれば疑問が残る。例えば、あることに熱中しているときはその他のことは考えることは難しい。認知バイアスは思考の範囲を狭めて正しいとされる概念を遠ざける。また感情が強すぎて客観的に問題を見ることができないこともある。これらの例はフレームがあるからこそ別の視点から物事を考えることができなくなってしまう、フレームがあるがゆえの人間的課題だろう。
だが、フレーム構造(もしくはシェマ)といった概念を作り上げて、目的に対してフレームを適応させてタスクに落とし込むという知的処理は機械にはまだ達成されていないことだろう。感情や思い込み、欲求など今までの機械学習が外側においていたことを利用して、機械が主観的なフレームを構築するという方法も1つの方法ではないかと考える。
タスク依存性があるからこそできること
機械はタスク依存性があり、フレームを作れないとしよう。それでは強化学習の研究は意味がないのだろうか。そうではない、タスクを限定するとその範囲で様々な方策を作る作る強化学習は、人間の与えることができるタスクの限界を示すことができる*2。また、機械にタスクを解かせることで、人間の思考を再確認することも可能だろう。
そして、タスクに対しては機械は様々なアプローチを、「ありえたかもしれない」解法取ることができる。それは、自分勝手にフレームを作ってしまう人間より新しい知見を与えることもある。
もう一度AlphaZeroを見てみる。
Alphaシリーズの一番最初であるAlphaGoは、2016年李世ドルと争い4対1で勝利した。このときのある対戦でこんなことが起こったそうだ。この情報は私が聞いた話であり、信憑性を高めるためにいろいろ調べたが直接その話を裏付けるものがなかった話である。話半分で見てほしい。AlphaGoがある手ー黒37手だったかもしれないーをうったとき、多くの囲碁関係者はAlphaGoの負けだと思ったらしい。なぜならばそれは人間からすると「ありえない」手だったらしい。しかし、どんどん局面が進むたびにおかしな現象に出くわした。その黒37手がどうもすごく効いているらしい。あそこに打ったのはそういう理由だったのかと気づいたときには、李世ドルの敗北は決定していた。
このことを単に機械が人間に勝利した強化学習すごい!捉えてもよいかもしれない。しかしフレーム問題の観点から考えると、申し越し踏み込んだ捉え方ができそうだ。すなわち、「人間がフレームを作ったがゆえにたどり着かなかった正解に、機械はフレームを作れなかったがゆえにたどり着いた」ということである。
AlphaGoの後継機AlphaZeroも同様である。AlphaZeroの棋譜を見ると、人間からは少し考えられない動きをした局面もあったらしい。例えば「王をど真ん中に打つ」という手である。人間はそんな手を考えない。私は将棋に全く詳しくないので王をど真ん中に打つというのはどういうことか理解はできないが、取られてしまったら負けてしまう駒をど真ん中に置くというのはあまり「美しくないだろう」。人間が勝手に作ってしまっている「強い棋譜は美しい」というフレームから逸脱しない限りこの手は出てこないはずだ。*3
これは何を意味するか。タスクが存在し、計算機資源が大量にある、そして強化学習のテクニックがあれば、人間が気づかない新しい発見を機械が与えてくれる可能性があるのだ。機械はフレーム問題を解決していない。しかし、フレーム問題を乗り越えているのかもしれない。
DeepMindではAlphaZeroの棋譜をみた羽生9段の言葉を紹介している。
Some of its moves, such as moving the King to the centre of the board, go against shogi theory and - from a human perspective - seem to put AlphaZero in a perilous position.
But incredibly it remains in control of the board. Its unique playing style shows us that there are new possibilities for the game."Yoshiharu Habu, 9-dan professional, only player in history to hold all seven major shogi titles
フレーム問題を乗り越える人工知能
今の拙い考察でフレーム問題への解法が2つできそうだ。
1つはタスク依存性の考えをやめて、人間がやっているように感情や欲求、知識をこねくり回してフレームを作ってしまうということ。世界のモデル化かもしれない。World Modelsももちろんその1つだと思う。だが範囲はもうちょっと広く主観的な考えも含んでモデル化するとどうなるだろうかと考えてみたくなる。[1604.00289] Building Machines That Learn and Think Like Peopleは幅広い世界モデルを考えているが感情や欲求など主観的なモデル構築は言及されていない。今後の方針としては、世界モデルをもう少し拡張する方向に見つめ直す必要もあるのではないか。
もう1つは、フレーム問題を乗り越える機械を人間の系に加えてしまうという方法だ。IA(Intelligence amplification)に方針を切り替え、フレームを作る人間とフレームを乗り越える機械の共同作業を広げるのだ。餅は餅屋に戦法とでも言っておこうか。今この共同作業はゲーム界隈では盛んに行われているが*4、これを研究でもやってみようとするのだ。
先に程示した、トンチ解法を生み出してしまった論文を例に取ると、研究者はそのようなトンチ解法を出してしまったがゆえに更に良いあたらしい関数にたどり着いた(回りくどいという指摘もあるが)。だが、なかなかこういう「失敗」を論文に書かないだろう。だが、フレームが無いゆえに、トンチ解法を生み出してしまうように、学習中に起きてしまった人間の意図をとってくれながったゆえの失敗を「機械の新しい発見」としてプラスに捉えてしまうのはどうだろうか。
人工生命の研究ではこのようなアネクドートを集めて再現性がないし目的にそぐわないけど面白い発見・驚きだったというものを集めようというプロジェクトが動いている。
それを強化学習(広く言ってしまったら人工知能だが)でもやっちゃおうということである。トンチ解法や想像もしていなかった方策、1度きりで発生した方策を集めることで、人間の取りうる思考の幅を広げることは可能ではないか。人間はその知見を利用して自身のフレームをアップデートする。そして新しい人工知能の研究に活かすのである。その中にタスク依存性を解決する方法がもしかして見られるかもしれない。
認識フレーム問題を解決するために
結局の所、人間もフレーム問題を解決できていないのかもしれない。しかし個々にもっているフレームが無いと何もできないという指摘をする哲学者や研究者もいる。フレームがあるからこそ人間は有限時間でものごとを負えられるのだと。しかし、一方でその結果として固まったフレームから離れることが苦手な人もいる。 そうするとこれは人間への逆フレーム問題として考えることができる。でネットはそこまでの拡張は望んでいないかもしれないが、フレームを考えるということは、フレームが存在しないがゆえに起こってしまう問題ととフレームが存在してしまったがゆえに起こってしまう問題両方捉える必要があるのかもしれない。
人間は幸い、他者による自治的な協調作業によってフレームを見つめ直すことができる。自由自在にフレームを操作し、フレームそのものを広げることが可能である。(しかも計算時間は事実上同じで!)機械は未だその領域まで踏み込めていない。だからこそ、人間が気づかなかった新しい概念を生み出し、それを人間が取り込むことで、人間に気づきを与え新たなフレームを構築することも可能だろう。
また、機械がもしフレームを構築できるようになったら、更に人間の手を介在しない目的に対する新しい結果が現れるかもしれない。
長くなったがとりあえず認識フレーム問題とタスク依存性から考える話を一旦終えることとする。
ご意見やご感想がありましたらコメントをぜひよろしくお願いします。また間違いの訂正もぜひよろしくお願いします。
*1:ところで、汎化の研究で個人的に好きな研究がある。World Moldes[Ha+2018]では、状態入力に予測モデルを組み込み(Dreamと本文中では表現)学習している。この表現は与えられた状況だけでなく、あり得るかもといった世界も表現することが可能となる。機械が取りうる知識を内部モデルで時系列的に処理し、不確実性をもたせているため、かっちりとした環境(ある意味タスク)を想定した今までの強化学習とはまた少し毛色が異なって見えたためだ。
*2:これはちょっと議論が必要かもしれない。タスクの与え方によってはトンチ的方策が現れてしまうこともある。[1704.03073] Data-efficient Deep Reinforcement Learning for Dexterous Manipulation
*3:はずだと言っているのは、私が全くこれらのボードゲームに詳しくないからだ。チェスに至っては全く知らない。AlphaZeroの論文をぱらっと見たとき、チェスの項目が勝数が少なく、引き分けだらけじゃないか、なんで威張ってんだこいつと思ってしまった。だが研究室の後輩から「チェスは先手必勝が存在する」と聞いて納得した。つまりAlphaZeroは後手になると「引き分けに持ち込む」戦法に打って出ていた、らしい。
*4:そのような対戦も始まっていると聞く。これもまた聞きなので信憑性は少ないが
認識フレーム問題とタスク依存性について
一番最初のテーマはフレーム問題を取り上げたい。このフレーム問題は 1969年第1次AIブームの時にジョン・マッカーシーとパトリック・ヘイズが提唱した問題 (McCarthy & Hayes 1969)である。
一番始めにマッカーシーらが提唱した問題は論理ベース(一階述語論理)による問題でだったが、後に様々な研究者が定式化を行った。最終的に有名な「フレーム問題」はダニエル・デネットによる「認識フレーム問題(Dennett 1978)」であろうと思う。ちなみにデネットはAI研究者ではなく哲学者である。
日本語のフレーム問題をWikipediaで調べるとデネットによる定式化しか出てこない。しかしスタンフォード哲学辞典や英語で書かかれたWikipediaでは、ちゃんとマッカーシーの問題も書かれいる。フレーム問題を取り上げるときに、マッカーシーによるフレーム問題と、デネットによる認識フレーム問題を正しく分けて考えないといけない。
ちなみに論理フレーム問題はマッカーシー自身が解決を試みており、様々な解決方法が提案されている。多くの研究者は「論理フレーム問題」を深刻な問題としてみなしていない。しかし、デネットによる「認識フレーム問題」はどうなのだろうか。これを考えてみたいと思う。(以下、フレーム問題を記述するときは「認識フレーム問題」のことを指す)
The Frame Problem (Stanford Encyclopedia of Philosophy)
認識フレーム問題の例
日本語版のWikipediaには認識フレーム問題の概要が示されているのでそちらを引用する。
現実世界で人工知能が、たとえば「マクドナルドでハンバーガーを買え」のような問題を解くことを要求されたとする。現実世界では無数の出来事が起きる可能性があるが、そのほとんどは当面の問題と関係ない。人工知能は起こりうる出来事の中から、「マクドナルドのハンバーガーを買う」に関連することだけを振るい分けて抽出し、それ以外の事柄に関して当面無視して思考しなければならない。全てを考慮すると無限の時間がかかってしまうからである。つまり、枠(フレーム)を作って、その枠の中だけで思考する。
だが、一つの可能性が当面の問題と関係するかどうかをどれだけ高速のコンピュータで評価しても、振るい分けをしなければならない可能性が無数にあるため、抽出する段階で無限の時間がかかってしまう。
これがフレーム問題である。
あらかじめフレームを複数定義しておき、状況に応じて適切なフレームを選択して使えば解決できるように思えるが、どのフレームを現在の状況に適用すべきか評価する時点で同じ問題が発生する。
ハンバーガーを買おうとするときに「新宿に行って、カラオケに行く」という選択肢もある。でも普通の人間はそのような選択肢を取らない。つまり、
マクドナルドを調べる→映画館を調べる→新宿に行く→映画を見る→マクドナルドに行く→店の店員に「スマイルください」という→恥ずかしくなって、帰る→スタバに行く→コーヒーを買う→マクドナルドに再度行く→ハンバーガーを買う
といった上記の選択肢を取ることは多分ないと思う。よほどのあわてんぼうさん出ない限り・・・。「ハンバーガーを食べる」という行為には無限の可能性がある。ところが意図的に人間は遮断している。「ハンバーガーを食べよう」としたときに「映画館を調べる」や「スタバに行く」という行為は、そのタスクの中で重要度が低いからだ。関連性と言ってもいいかもしれない。
「ハンバーガーを買おう」という時に、必要で重要な選択肢のみをフレームで囲って、その他の選択肢を思考から除外している。しかし、機械はそういう人間のようにフレームを囲って処理することができない。永遠に可能性を考えてしまう。無限回思考を行わないために、どこかで踏ん切り、つまり「フレーム」を作ることができない。副次的に発生していまう関係ない現象をそもそも「フレーム」の外に追いやることができない。
このような、「思考を無限後退にしてしまう問題」を「認識フレーム問題」という。ここまでの説明は一般的なフレーム問題の解説である。
本当にフレーム問題は解決できないのか?ー強化学習との関係性ー
さて、現在の人工知能はどのようにフレーム問題を解くことが可能だろうか。少し考えてみる。こういう問題を解くときは、すこしフレーム問題から離れて問題を捉えることも大切だと思う。
そこで、フレームを作る作らないを一度よすけにおいて、このような問題を「あるタスクを達成するための最適解はなにか?」という大きな問題で考えてみる。この問題を解くための人工知能研究はあるだろうか。多分ある。それが強化学習(Reinforcement Learning)である。
強化学習にもいろいろな種類というか設計方針があるため一言で説明するのは難しいのだが一言で言うならば、「タスクに対して、適切な方策を学習する方法」である*1。この強化学習は、教師あり学習とは異なり、答えが完全に用意されていない。しかし、環境内で試行錯誤を繰り返していくうちに、タスクにピッタリの方策を学習していく。試行錯誤を評価するのが、環境から与えられる報酬である。報酬によって、方策を更新していく。*2
逆に言えば、タスクがしっかりしており環境からの報酬が定式化されておれば、強化学習は幅広い問題を解くことが可能となっている。
例えば、2018年最新の強化学習アルゴリズムR2D2はAtariゲームベンチマークで昨年のアルゴリズムApe-Xをあっという間に置き去りにした。*3
Recurrent Experience Replay in Distributed Reinforcement Learning | OpenReview*4
また、R2D2でも難しいされているAtariゲーム「Montezuma's Revenge」を探索していない場所に対してより多くの報酬を与えるというギミックを導入することで人間を超えるスコアを叩き出した。
Exploration by random network distillation | OpenReview*5
さらに、忘れてはいけないのはDeepMindによる[Alpha]シリーズではないだろうか。(勝手に私が言っているだけだが)。最新のAlphaは同じ設計で囲碁・将棋・チェスの3つのゲームをほぼ同じシステムで現在最強と呼ばれる他のマシンを圧倒することができるようになった。
今回はタスクがわかりやすいゲームをあげたが、近年の強化学習では、歩き方の創発やロボットの制御、環境の近似化などを達成することができるようになってきた。少なくとも様々なタスクを達成可能している。強化学習の種類に関しては次のQiitaが詳しい。
もう一度ここで最初の問題に戻ってみる。「あるタスクを達成するための最適解はなにか?」という問題に、強化学習はどうやら答えられているようだ。まだまだ強化学習には研究しなければならない課題があるが(汎化の問題など)、タスクが決定し、報酬系を正しく与えることができれば、最適解を導くことは可能である。
試行錯誤中(学習中)はとんでもない方策を導くこともあるかもしれないが、少なくとも学習の最終的な到達点においては「思考を無限後退にしてしまう」という問題は発生していない。また、様々な選択肢があるにもかかわらず環境の変化に応じて柔軟に行動の選択肢を変化することもできる。フレームを適切に選んでいると考えられる。
Wikipediaの例で示された問題を考えよう。つまり現段階の強化学習において、「マクドナルドでハンバーガーを買いなさい」というタスクと、ハンバーガーを買うための報酬系が正しく定式化できれば、強化学習を搭載したエージェントは、ハンバーガーを購入することが可能なのだ。風が吹いたら看板が落ちるかもといった今までよく言われていた、フレーム問題はそこに発生することはない。
こう考えると強化学習の研究において(もしくは人工知能研究において)、強化学習の挑戦的課題が残っている今、フレーム問題というものを考えることは無意味なのかもしれないのか。
フレーム問題は解決済み -フレーム問題に見る、AI史の闇ー – AIに意識を・・・ 汎用人工知能に心を・・・ ロボマインド・プロジェクト
上記のサイトでもここでも同様のことを論じていた。*6
タスク依存性からみる強化学習とフレーム問題
認識フレーム問題を「あるタスクを達成するための最適解はなにか?」というふうに捉えると、強化学習によって達成できそうだ。しかし、ここで問題を一歩勧めたい。現実的なタスクは静的なものばかりだろうか?
ある1度マクドナルドを買うことができた強化学習を搭載したエージェントはその獲得した知識利用して再度マクドナルドに行こうとした。
しかし、マクドナルドが臨時休業していたり、ものすごい長蛇の列で購入に1時間程度かかったり、マクドナルド付近がポケモンGoのプレイヤーでたどり着けなかった場合はどうするのか。
「じゃあまたそういうときのためにタスクを変えて強化学習しよう。今まで学習につかった事前知識を利用しよう」
なるほど、そうすると、寒い中空きもしないマクドナルドの店の前で凍えながら(エージェントが凍えることはあるのだろうか?)「ビッグマック・・・ください」とは言わないだろう。エージェントは別の報酬を利用して新しいタスクを解く方策を学習した。
環境とタスクが変わるたびに学習を行えば、あまり問題はなさそうだ。しかし言い換えると、「ハンバーガーを食べる」という目的をたてるたびに、環境外圧によってタスクの微妙な修正が必要かどうか確認を行い、必要に応じて内部の知識を再構築しなくてはいけない。学習が終了した時点で環境が変わってしまったら、タスクを書き換え、再度内部の知識を構築し直さなけばならない。*7
もう一度自分が学習した知識をベースにして再び学習を始めるのだ。タスクを少しいじるだけで、学習した内部知識はある意味使い物にならない。タスクごとにそれを解決する強化学習。またタスクが変わった・・・それに対応する強化学習・・・。
そうすると、このような「タスクに対して依存性がある」強化学習では、最終到達点であるタスクがコロコロ変わってしまうと、環境や報酬系を再定義して、再び学習を行い新しい方策を見つけなければいけない。タスクが定常状態になるまで繰り返さなければいけない。そう考えると、エージェントはマクドナルドにたどり着くことはできなくなってしまうのではないか?
前章まで話していたフレーム問題の回避は、タスクが静的という仮定のもと考えられた話であった。今までのフレーム問題は、風がふいたら看板が落ちるかもしれない、さあどうしようといったミクロレベルを話していた。これは強化学習で対応できる。風が吹いて看板が落ちることは報酬に関係ないからだ。
しかし実環境を考えると、タスクは微妙に修正を繰り返してしまうというタスクに対するマクロレベル問題を考える必要になる。認識フレーム問題から逃れられないのではないか・・・。
「そうならないようなシステムを作ろう」としたとき、再びタスクに対して依存性が発生する。どのタスクを選択するかというメタタスクは、またタスクの可能性や変化によってメタタスクを書き換えなければいけないからだ。
またこういう問題も考えられるだろう。「ハンバーガーを食べる」という目的を達成するために一番適切なタスクを機械は生成することはできるだろうか。目的は固定されていても、タスクレベルではやはりダイナミックに状況が変化してしまう。その目的に合うタスクを考えることは、やはり環境や報酬によって容易に変化してしまう。これもメタタスクの問題に分類されるだろう。
このように、機械学習についてくるタスク依存性から抜け出さない限り、強化学習を持ってしてもマクロレベルのフレーム問題は回避できなくなってしまうのではないか。
閑話休題して、人間の場合を考えてみよう。
多くの人が「マクドナルドじゃなくてモスバーガーにでもしようか」「せっかくだから相模大野まで足を伸ばしてマックを食べるか」「いや、新百合ヶ丘のほうが駅からマックの距離近いぜ」などと言ってそのマクドナルドではなく別のマクドナルドや別のハンバーガーショップに行こうとする。簡単である。ハンバーガーを食べようとしたときにそのタスクを達成するためのフレームを柔軟に構築することができる。
この人工知能と人間の違いはどこから生じるのか。なんとなく、このフレームに対する柔軟性が何かヒントになるのではないか。そしてフレーム問題を解決できない人工知能は結局人間に及ばないのか。いや多分、決してそういうことにはならない。AlphaZeroがその1つのヒントを与えてくれている。次の話ではテーマを深掘りしていきたいと思う。
ご意見やご感想がありましたらコメントをぜひよろしくお願いします。また間違いの訂正もぜひよろしくお願いします。
*1:いろいろな資料を漁ったが、じんべえざめ (@jinbeizame007) | Twitterさんの資料が非常にわかりやすい
*2:注:この説明はすごくアバウトである。本当にアバウト。Web上には様々な強化学習の資料や勉強会スライドがあるから、真面目にそっちを見た方がよい。私もお世話になっております・・・
*4:現時点で、ICLR2019でAcceptされている。これでPosterなんだからどだけレベルが高い国際会議かわかるでしょうに
*5:ICLR2019:Accept(Poster)
*6:ただこのサイトでは論理フレーム問題と認識フレーム問題を混同しているフシがある。最後で解決済みと言っているのだが、迷路のような特殊空間で起きること言っているが、現実世界ほどタスクが常に変化してしまう迷路空間はないような気がする。このへんはもうちょっと議論が必要かもしれないが
*7:今更ながら、目的とタスクの違いについては別途説明が必要であると思ったのでここで述べる。私は目的というのはかなり大きな範囲でとっている。例えば今回の例だと「ハンバーガーを食べる」である。その目的を達成するために様々なタスクが存在する。例えば「マックで食べる」というものタスクある。強化学習もタスクレベルの方策を与えていると考えている。
「主観的」人工知能考察をしてみようと思う
人工知能研究は面白い。そして情報量が膨大である。
3日ほどサーベイをほっぽりだし自分のべつの趣味に没頭しただけなのに、読まなくてはいけない論文がどんどん出てくる。ものすごく研究のペースが速いのだ。
ある論文の冒頭に、「人工知能研究のスピードは”rapid”であり・・・」と記述があった。著者たちは勘違いしている。もはやRapidペースではなく、"Limited Express"ペースと書くのが正しいだろう。むしろ"SHINKANSEN"ペースと書いてもいい。いや、"SST( Supersonic transport:超音速旅客機)"ペースと書いても査読者は納得するだろう。(そのような形容詞はない)
2018年人工知能界隈で、「WoW!」といわれた論文10つをあげてくださいといわれたら何をあげるだろうか。すでにそのような記事がでている。
自然言語処理系の論文が多いなとも思いつつ、事前学習に関する研究、連続量データに関する研究がトップ10に入っていた。
その中でも、World Modelsは自分の研究の中でも重要な位置づけを持つ論文となった。(このWorld Modelsの考えは、[Building machines that learn and think like people]を参考にしているはず)
もちろんこの中にない論文で、興味を掻き立てられる研究もたくさんあった。
自分の研究と関連付けるならば、ICLR2018で発表された論文の中で心を惹かれたのがこの論文。
[1804.02341] Compositional Obverter Communication Learning From Raw Visual Input
エージェントが人間の力に頼らず言語創発するというもの。テクニック的には結構シンプルなものである。しかし、ゼロショット学習に対応していたり、形容詞的な言語文法の自律的構築が見られるなど、シンボル生成研究のなかで、特徴的な研究となっていた。
また、現段階ではICLR2019の予行集であるものの、ATARIゲームベンチマークで最高得点を出したR2D2も興味深い。2018年度最強であった、Ape-Xをあっという間に置き去りにした。LSTMと経験再生と分散学習を組み合わせたアルゴリズムになっているらしい。
Recurrent Experience Replay in Distributed Reinforcement Learning | OpenReview

さらに、OpenAIからは、DQN系列(価値ベースの強化学習)で苦労が続いた、 Montezuma’s Revengeというゲームにおいて人間のスコアを超えるアルゴリズムが登場した。好奇心(内部パラメータ、探索していない部分に向かわせる)に基づき環境を探索させることでスコアを伸ばした。
これらの解説は日本語でも出ている。(勉強になっています。ありがとうございます。)
これだけ新しい研究が生まれ、人工知能の各分野に対して新しい発見が常に起こっている。挑戦的な時代で研究できることを面白くないといえるだろうか?好奇心をくすぐられる研究分野であると思う。
それでも、物足りなさを感じることがある。それは、分野を横断した「人工知能そのもの」に対する考察である。
これらの研究では人工知能の技術・能力に関する考察が必ずなされる。つまり人工知能の分野(たとえば、画像認識、強化学習、自然言語処理など)でどのような成果を挙げているか、どのような研究が期待されるかについては見えてくる。
だが、人工知能そのものについての考察が見られない。分野ごとの方向性は見えても人工知能研究全体の見通しが見えてこない。
分野に限った論文だからだろうか。ある分野の能力が向上したという記事は新規性がわかりやすい。タスクやベンチマークに対して比較することが可能だからだ。
しかし「知能」にどれだけ近づいたかというベンチマークは存在しない。何かを達成したから「知能」になるというわけではない。それがわからないから、知能的な所作を利用して何かをしよう分野を研究している。いわゆる弱いAIである。
本当に人工知能を作りたいと思うならば、大切なポイントは「人工知能そのもの(強いAI)」にこれらの研究がどのように影響を与えているかという視点ではないだろうか。私は、ここにちょこっとだけでも知見を与えたいと思ってしまった。
能力や分野、技術の面から話す人工知能をやめて、人工知能研究全体として興味深い・意義深い研究やインパクトのあるアプリケーションが、人間や生物が行っている知能とどのような関連(対比)を持つかということを考えようという視点である。この視点は非常に「主観的」である。
しかし、「主観的」だからこそ、知能を横断的に解釈することができるのではないか。今まで分野の範疇でしかかたられることのなかった技術がほかの分野と結合して、あたらな可能性を生み出すことができるのではないか。知能という興味深い分野について
もちろん、技術を知らないと主観的であっても話すことができない。人工知能の技術に基づいて、それが知能全体にどのような影響を与えるのか。どこに関連づけられるのか。
そんな、「主観的」な人工知能考察をやわやわ始めようと思う。やわやわなのは、自分のペースがゆっくりであるからだ。
まずは、書いてみることからはじめようと思う。不勉強なところもあるかもしれない。勉強しつつ、自分の研究をしつつ更新をしていこうと思う。